Introduction to HTTP and the request/response cycle
March 5, 2020
When our user interface is communicating with servers or generally requesting information, there are some concepts we need to know to understand what exactly is happening.
We don’t need to go deep into each one of these concepts as most can be a course topic on their own, but having a general understanding will really help us.
The first concept is the client-server model:
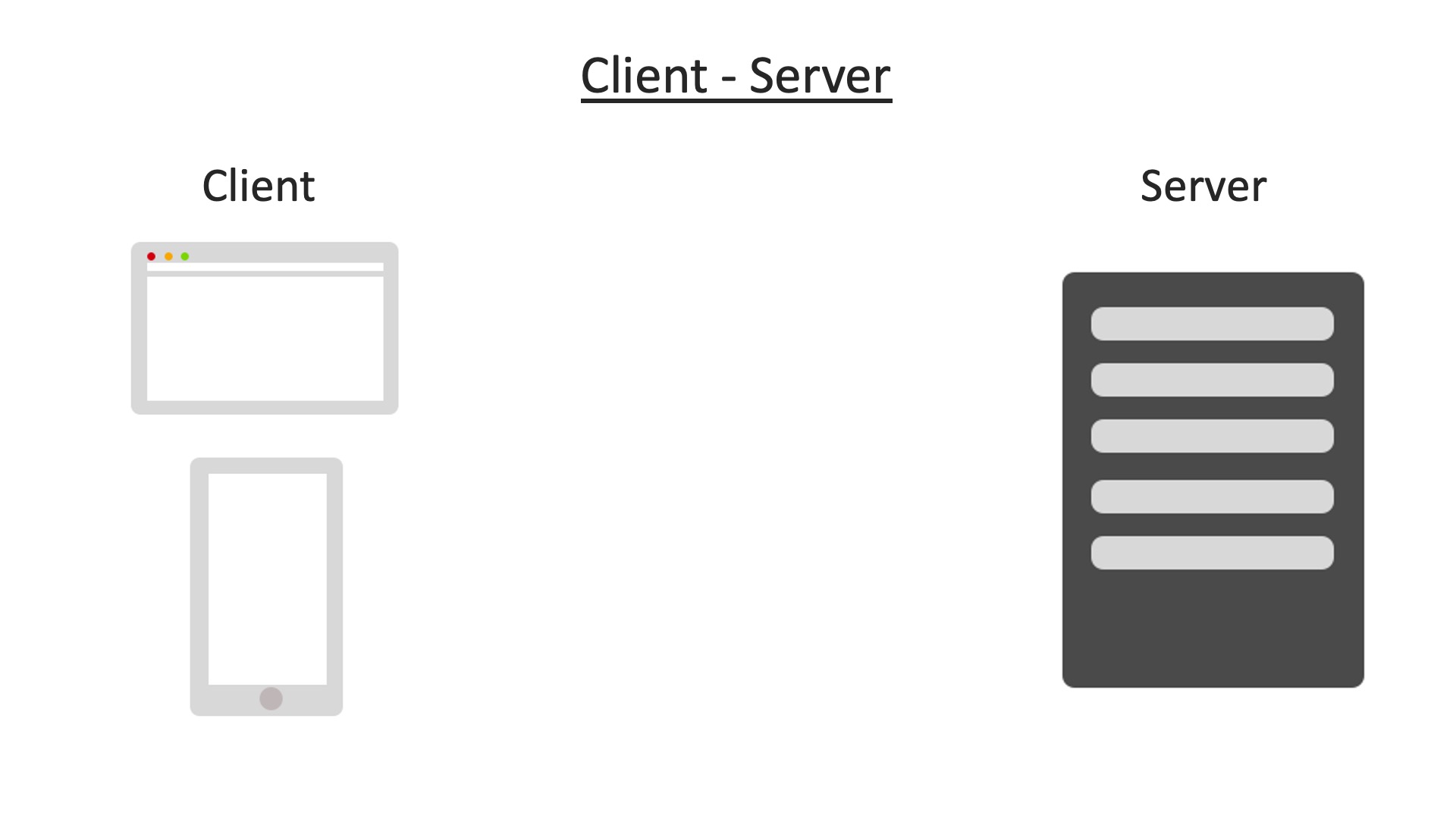
As you see here, on the left we have some examples of a client, a client can be the web browser, a phone, or even the terminal on our computer, basically the client is the one which makes the requests, such as requesting the web page we want.
On the other side we have the server which provides the resources or services the client will need, such as our web page which it will send back to the client if it has it.
When a client makes a request, such as requesting a web page, this is called a HTTP request, HTTP stands for HyperText Transfer Protocol:
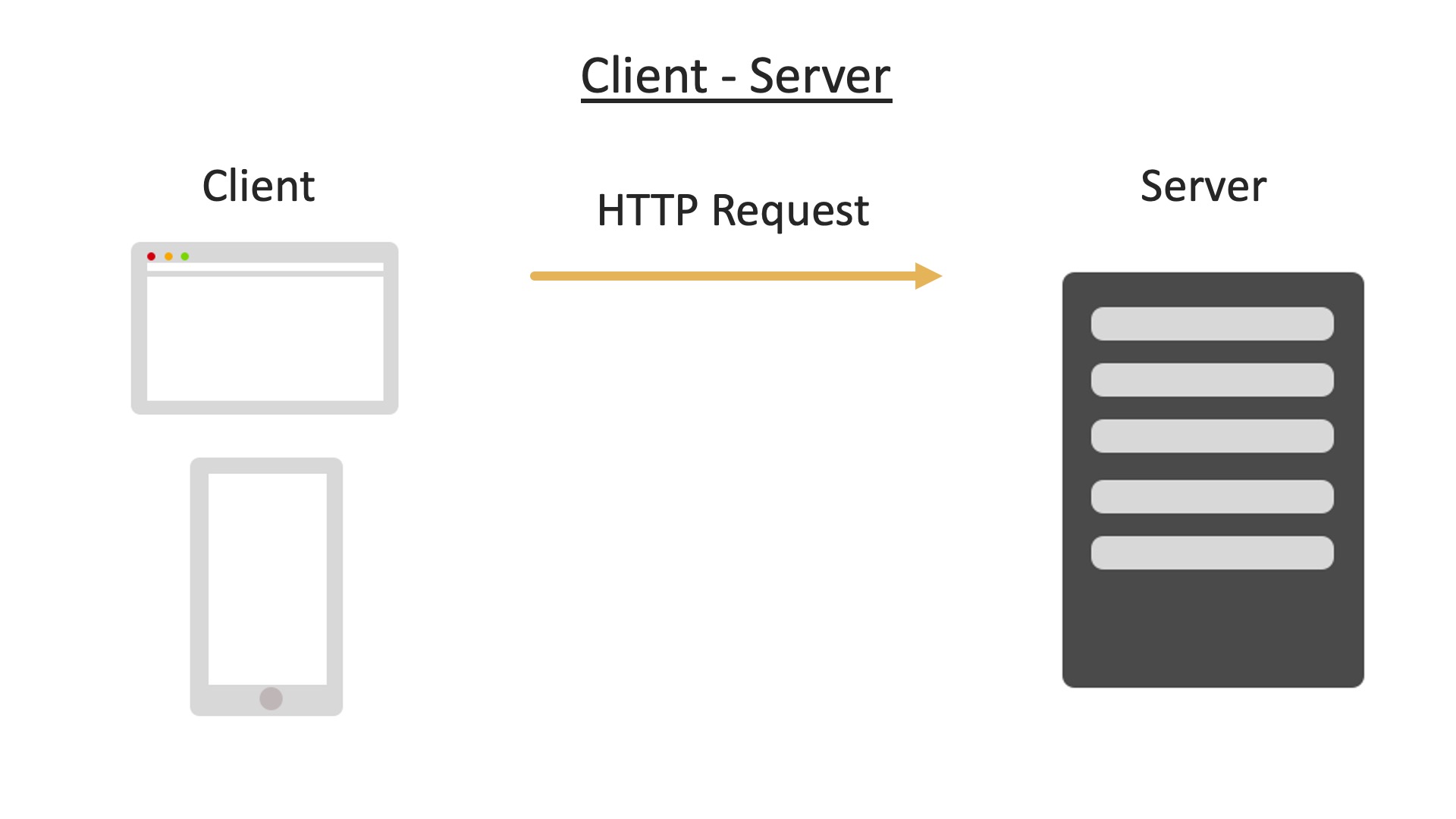
This is the standard or procedure used when transferring hypertext data across the web.
So, the client makes this request, and the server will try to respond to that request if possible:
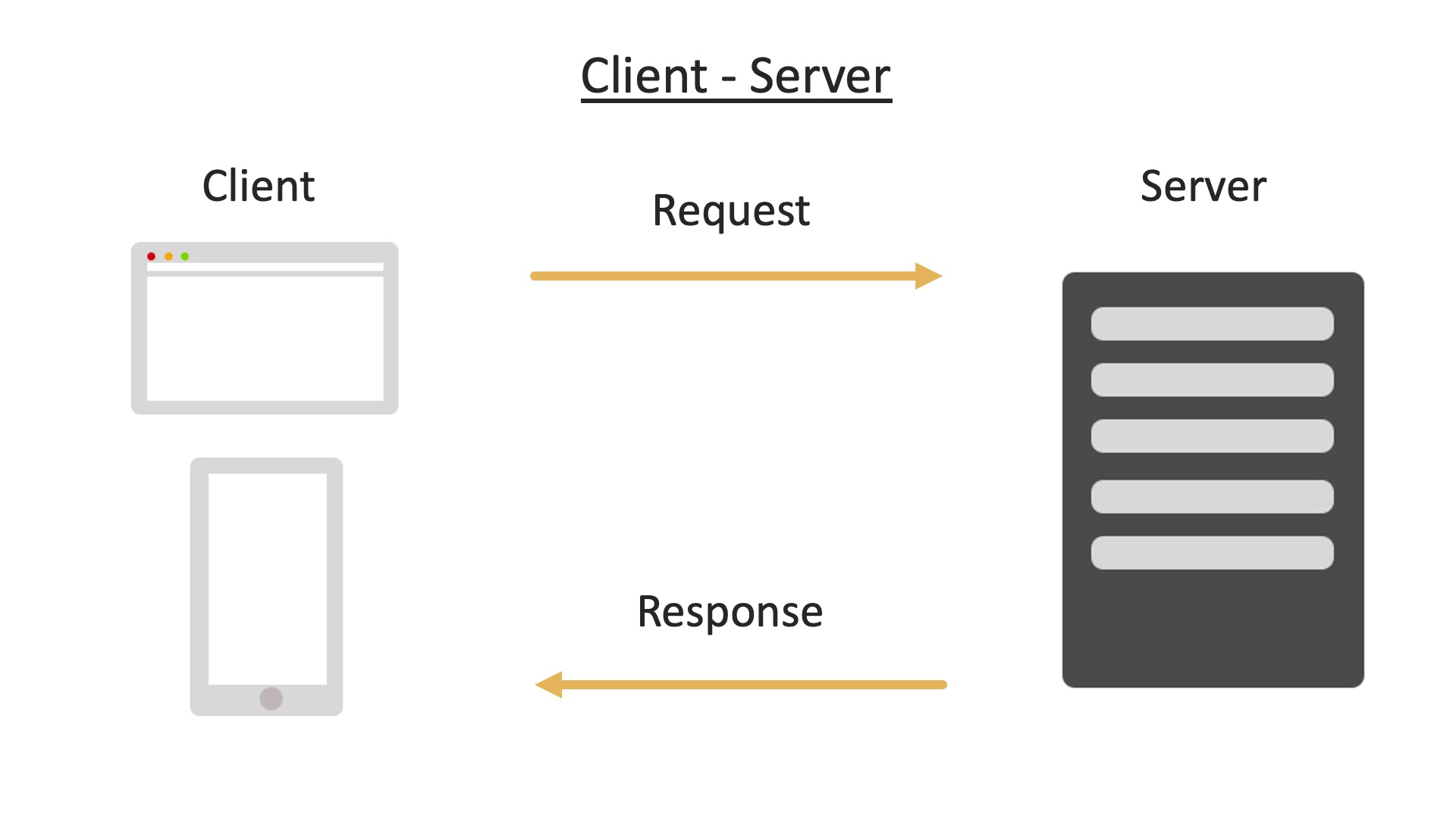
It may respond with things such as the HTML of a web page, images and any scripts which are needed.
Although this may sound complex, it is something which we do each time we use the browser.
For a real world example, you can head over to the browser and type in any URL, for this example I will use:
First of all notice this HTTPS at the beginning, this is like the HTTP we mentioned before, but nowadays HTTP Secure is more commonly used as it provides an encrypted version for greater security and privacy.
Once we hit enter, the web browser, or the client, is now making a request for this web page.
If everything went ok, the server responds with the requested page and it displays in the browser.
This request response cycle also works the same for other clients, even a computer terminal is a client too.
If you want to follow along, you can type into your terminal:
curl https://www.wikipedia.org
This cURL command can also make a HTTP request for a web page, and if we hit enter, we get all the HTML and CSS returned to us which makes up this web page:
chriss-iMac:~ chrisdixon$ curl https://www.wikipedia.org
<!DOCTYPE html>
<html lang="mul" class="no-js">
<head>
<meta charset="utf-8">
<title>Wikipedia</title>
<meta name="description" content="Wikipedia is a free online encyclopedia, created and edited by volunteers around the world and hosted by the Wikimedia Foundation.">
<![if gt IE 7]>
<script>
document.documentElement.className = document.documentElement.className.replace( /(^|\s)no-js(\s|$)/, "$1js-enabled$2" );
</script>
<![endif]>
<!--[if lt IE 7]><meta http-equiv="imagetoolbar" content="no"><![endif]-->
<meta name="viewport" content="initial-scale=1,user-scalable=yes">
<link rel="apple-touch-icon" href="/static/apple-touch/wikipedia.png">
<link rel="shortcut icon" href="/static/favicon/wikipedia.ico">
<link rel="license" href="//creativecommons.org/licenses/by-sa/3.0/">
<style>
...
The difference is a web browser knows how to handle this data and transform it into something visual for us to see, but the terminal does not, this is why we just see plain text.
When we make a HTTP request, there is various request methods we can use:
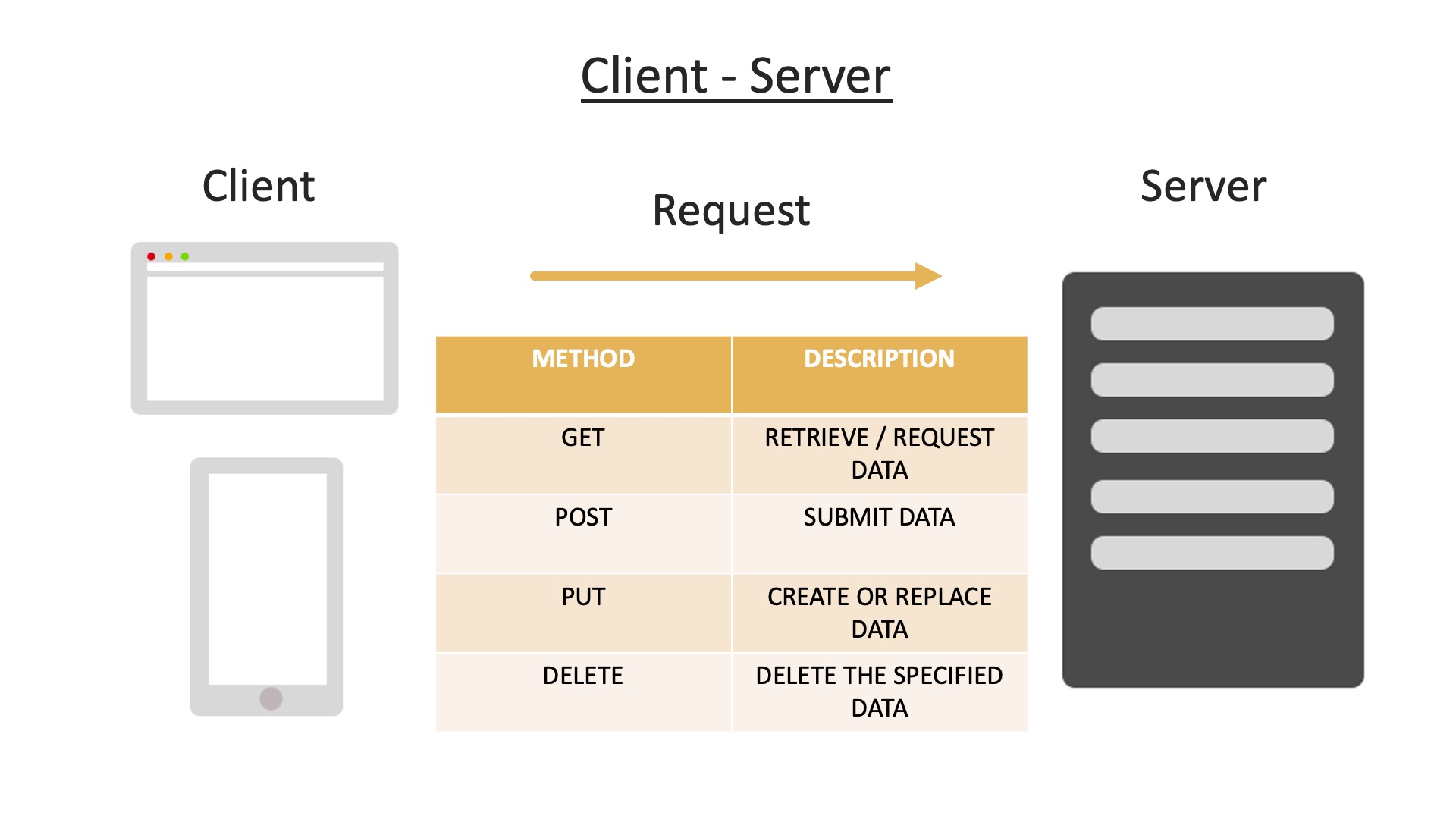
Here you can see 4 examples called GET, POST, PUT and DELETE, there is more than these 4, but these are common ones to get us started.
When we want to get a web page, or get some data, we use the GET request, a get request is what we use in the browser when we type in a URL.
POST will do the opposite and submit some data to the server for processing, such as adding a new record into the database.
Next, we have the PUT request, just like POST this will also submit some data to the server to process, however, the difference is, if the data or resource already exists, it will replace it.
This is used commonly for updating some data such as a user updating an email address.
The final one of DELETE is pretty self-explanatory, this will delete the resource or data specified.
When the server responds it will also respond with a status code too, there are may different responses, but here are some examples:
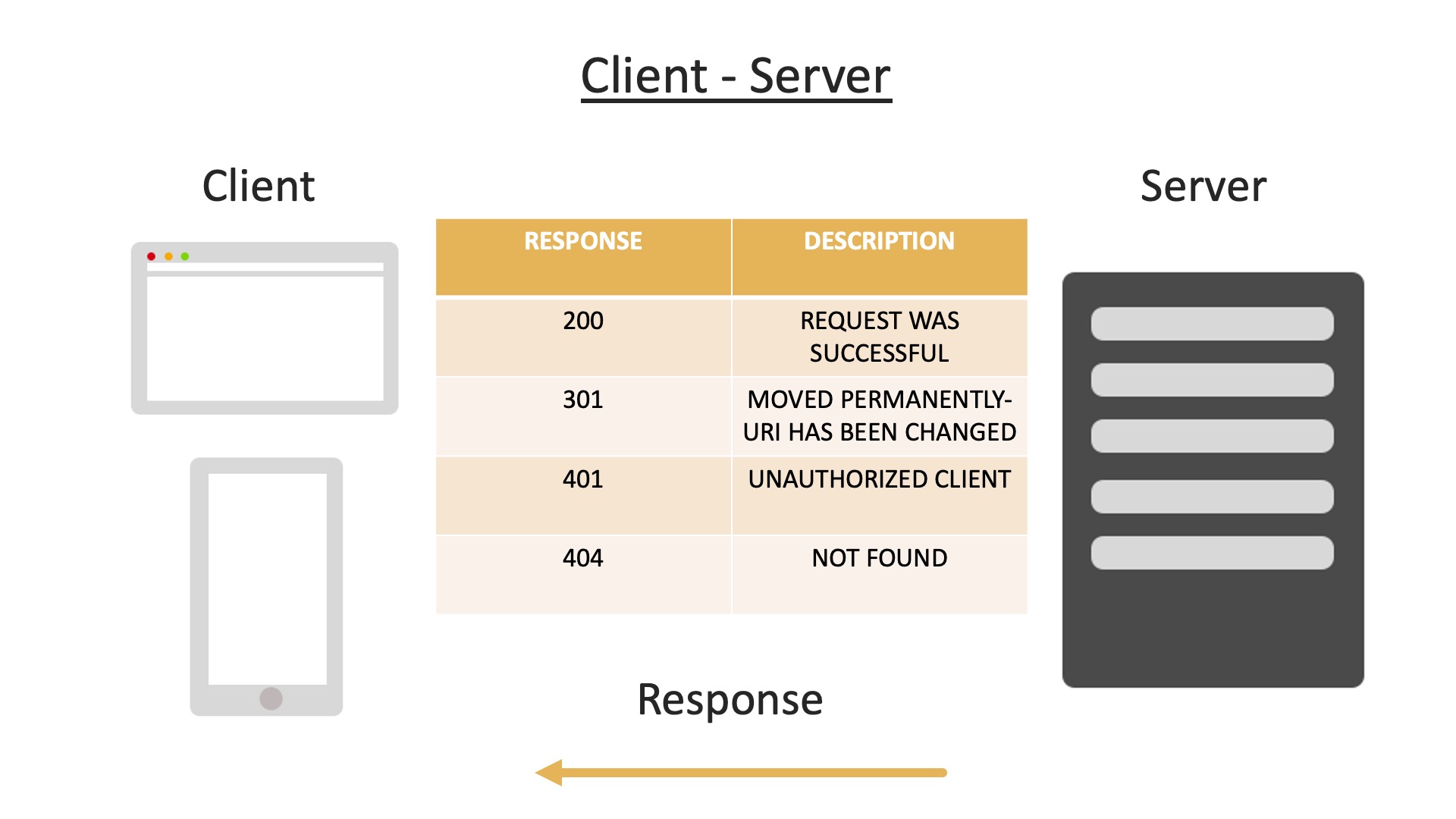
A code of 200 means the request was successful and the requested resource is sent back to the client in the body of the response.
301 is a redirection message, this means the resource we are requesting has been moved permanently and we usually get the new URI given with the response.
A 401 response means the client is unauthorised, usually requiring authentication before receiving the response requested.
404 is a common one you may have seen before when on the web, this is common when a page can not be found, such as when a user mis types in a URL.
You can find more status codes on the Mozilla website.
Although a lot of this may just appear to happen in the background by magic, we can get a better idea of what is going on in the browser developer tools.
Back to the wikipedia example page, in most browsers we can open up the developer tools with right click > inspect (or inspect element).
Click on the network tab, and refresh the page, leaving something like this:
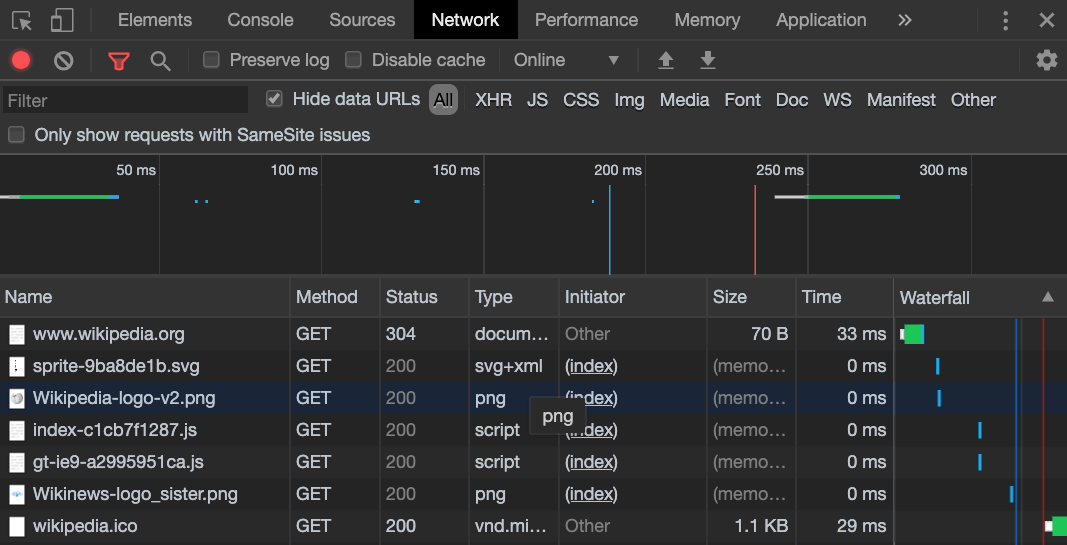
Here we see a list of the resources we are requesting such as our home page, images and scripts.
Also, we see many have the the status code of 200, which is a success as we looked at before.
There is also this status of 304 for the home page.
This means the page has not been modified since the last request, therefore, the browser can used what is called a cached version.
A cache is a temporary storage, browsers use a cache to store our web pages once visited so they can be accessed faster and also reduce the need to keep making server requests.
Near the top of the network tab, we have a check box to "Disable cache", click on this and refresh the browser:
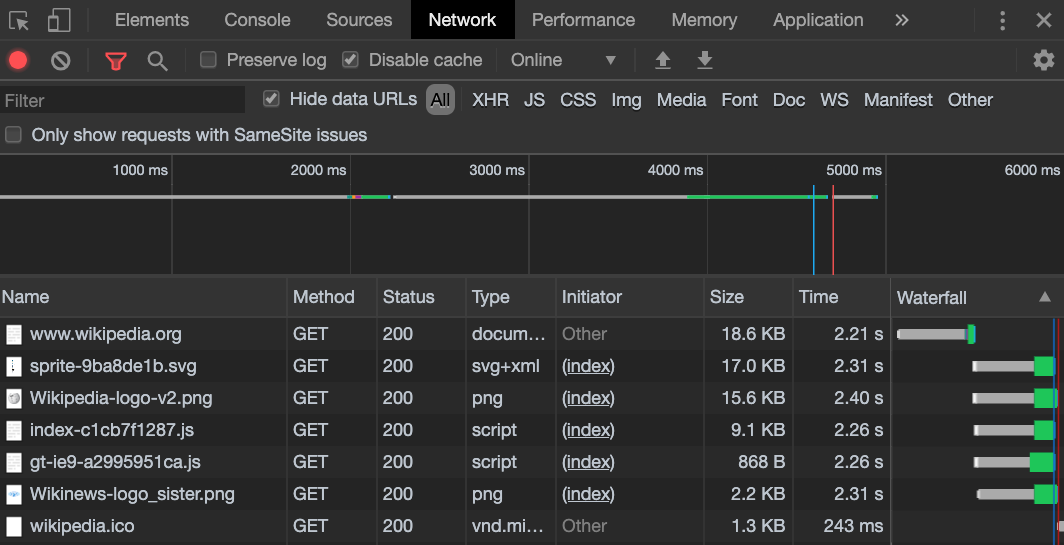
The status code is now back to 200, since we are no longer using a cached version, and we are making a new request for the page.
This is an overview of how things work between the client and server.
Even by having just a basic knowledge of these concepts will really help you understand what is going on behind the scenes and really help you as a developer.